









Maintenance Records And Mileage Helping Identify Dependable Used Cars

Used cars deserve careful attention before any purchase decision begins. Proper records along with steady mileage details help buyers understand previous care with greater confidence. […]
Beyond Appearance What Defines a Premium Rolex Super Clone Today?

Modern horology collectors analyze precise mechanical craftsmanship when evaluating alternative luxury timepieces. High-density stainless-steel alloys provide authentic physical mass during daily wear. Swiss movement engineering […]
TPD Claims Lawyers Advocating for Fair Compensation in Disability and Insurance Matters

Navigating disability and insurance disputes often becomes stressful when claims are delayed or denied. Many people require guidance to secure fair results when dealing with […]
Experience Cooler Summers With Affordable AC Service That Prioritizes Reliability

It shouldn’t cost a lot of money or be bothersome to stay cool in the summer. Consistent upkeep and responsive service that is adapted to […]
Legal Rights and Responsibilities of Students in Rental Accommodation

Many students find that renting a house is a big step toward freedom. But this change also brings with it often disregarded new legal rights […]
Fully Furnished Rental Apartments Ready for Immediate Move-In Convenience

Finding the ideal area to live sometimes needs juggling ease, accessibility, and speed. For people and couples looking for a continuous move into a new […]
Safely Utilizing Mail-Order Pharmacies to Meet Your Prescription Requirements
Offering unmatched convenience and usually large cost savings, mail-order pharmacies have grown to be a somewhat popular choice for getting prescription drugs. For people with […]
Navigate Estate Disputes Smoothly With Guidance From Skilled Probate And Estate Lawyers

Often resulting in years-long family strife, estate disputes can be emotionally charged and legally convoluted. Whether it’s arguments over the division of assets or challenged […]
Increase Cannabis Site Traffic with Powerful Link Building Campaigns

Your cannabis site needs more than occasional social media updates or sponsored ads to attract visitors. Get high-impact backlinks from relevant sites to build a […]
Access Restricted Chambers of the Catacombs for a Rare Adventure

Underneath Paris’s surface lurks a secret web of tunnels, bones, and enigmas. Although many tourists visit the usually accessible regions, few know that other places […]
Comparing Popular 5-Gram Carts: Which One Reigns Supreme?

As the cannabis market continues to evolve, 5-gram carts have emerged as a preferred option for heavy users and value-seekers alike. These high-capacity cartridges offer […]
Youth Basketball Excellence: arming European Expertise Young Athletes with

Our Youth Basketball Program is committed to developing young talent and encouraging personal development by means of basketball. Serving young athletes between the ages of […]
Innovative Concrete Solutions for Sloped Areas with Retaining Wall Installation

Both homeowners and builders can find great difficulties in sloped locations. Safety, stability, and aesthetic appeal all depend on good planning and sensible solutions. Retaining […]
Mold Matters: Control of the Menace of Mold Spores for Improved Health

Extended contact with mold spores can have major negative effects on the body and the psyche. Many people are unaware of the harm these microscopic […]
The Benefits of Implementing SEO for Business Success

Search engine optimization (SEO) is absolutely vital. To generate traffic, enhance user experience, and boost income, companies in all kinds of fields are increasingly turning […]
Unique Ideas to Spice Up Your Next Scavenger Hunt Adventure
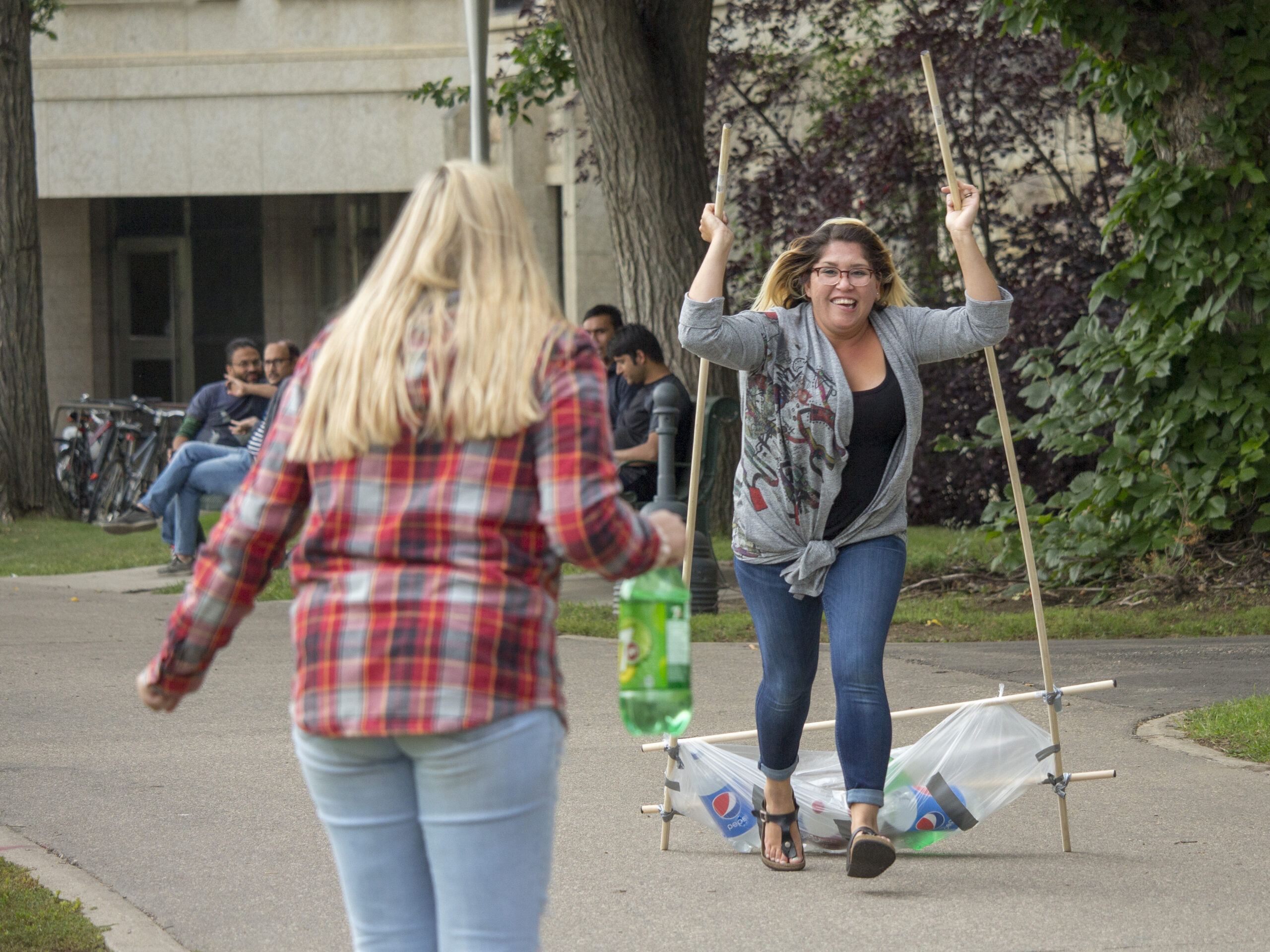
Treasure hunts are a terrific and fascinating opportunity to discover, compete, and value the big outdoors or maybe inside surroundings. They are also a classic […]
Supporting Little Smiles: Children’s Dental Mouthguards
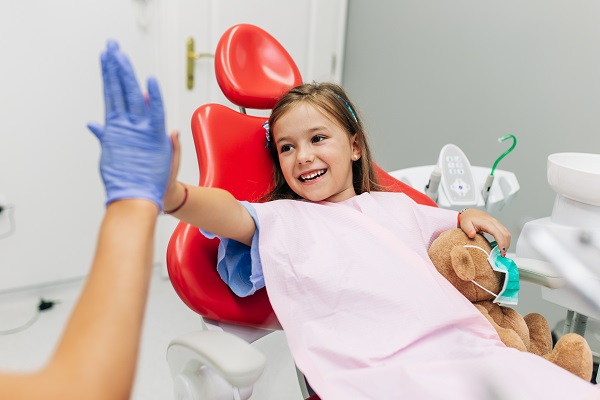
Safety of their child is the primary worry of any parent; thus, in sports and play, injury is always a possibility. Dental injury is one […]
Locked Out? Vancouver Residential Locksmiths Awavers are ready to assist!

Getting locked out of your house may be a frustrating and embarrassing event. Whether you broke a lock, lost your keys, or unintentionally locked yourself […]
Concrete Contractors in Venice: Trusted Experts for Your Projects

When it comes to major construction or renovation projects, hiring a reliable and skilled concrete contractor is crucial for ensuring quality results. Whether your intended […]
Rent a UTV in Phoenix: Your Key to an Exciting Adventure

For outdoor lovers seeking exciting excursions, Phoenix, Arizona, is not only a busy metropolis with desert settings and energetic culture. Renting a UTV is one […]
The Role of a Probate Attorney in Settling an Estate

Usually, a loved one’s estate proceeds through a legal process known as probate upon death. Especially in cases of conflicts, confusing wills, or large assets […]
Understanding What Best Results Dental Marketing Is All About

Getting new patients and making your dental business more visible online are two important things you can do to grow it. This is where Best […]
Shining Gateways: The Guide for Garage Door Excellence

Regarding home upkeep, one cannot stress the value of your garage door. Ensuring its seamless running not only guarantees your house and car but also […]
Complete Puppies: The Power of Professional Dog Training

Hire a professional dog trainer to help you create a happy home with your pet friend. Any dog, whether it’s a baby that likes to […]
Questions to Ask Before Hiring a Concrete Company

Whether a building project calls for a home driveway, a business foundation, or decorative concrete work, selecting a concrete company is a big choice. Choosing […]
Private Investigators: Precision and Privacy Inventors

The desire for professional support has exploded in the fast-paced world of today when privacy is under more difficult safeguard. Here is where private investigators […]
Learning Mobile Mechanic Magic: Easy Vehicle Maintenance Right Beside You
Every time your automobile requires a check-up or repair, are you bored with the trouble of going to a workshop? Imagine having experts visit you […]
How G9 HP Servers Enhance Data Center Efficiency

Modern companies are built around data centers, which offer the tools required to store, process, and protect enormous volumes of data. HP’s Generation 9 (G9) […]
The Environmental Benefits of Sustainable Building Practices in Real Estate

While sustainable building techniques benefit the environment as well as long-term financial sustainability, they have attracted a lot of interest in the real estate sector. […]
Why Luxury Modular Homes Will Shape Irish Sustainable Living Going Forward

The building sector is changing to fit contemporary environmental issues as the world keeps emphasizing sustainability. Rising luxury modular homes are one of the most […]
Lightning-Quick Response from Gold Coast Snake Catchers

The demand for dependable, fast, and effective snake removal services is growing among Gold Coast residents due to the increased frequency of snake sightings. Anyone […]
Lash Luxury: Customized Elegance Level Up Your Look

Get beautifully personalized lash styles from top choices made just for you. Imagine waking up every day with lashes requiring no upkeep and eyes already […]
Knowledgeable FCRA Lawyers to Correct Credit Report Errors

Not alone if you have found mistakes on your credit report. Many people become frustrated when they find false or deceptive material damaging their credit […]
Interior Design Firm vs. DIY: What’s Right for Your Home?

One of the first choices you will have to make when redesigning or remodeling your house is whether to work on the project yourself (DIY) […]
Why Annapolis Residents Choose Local Experts: The Benefits of Professional Car Detailing

For Annapolis inhabitants, maintaining the beauty and utility of a car is absolutely basic, especially considering the unique surroundings and natural events of the area. […]
Guiding Homeowners Through Common Repairs: Garage Gate Glitches

Every house owner is aware that the convenience and security of their house depend on a garage door. Like any mechanical system, garage doors might, […]
Harnessing Innovation: Courses for Corporate Growth

Harnessing innovation is crucial for corporate growth in today’s competitive landscape. Companies that prioritize innovation not only stay ahead of the curve but also drive […]
From Packing to Unpacking: How Our Moving Agency Makes Your Move Effortless

Moving to another home can be both energizing and overpowering. From figuring out possessions to packing them securely lastly unpacking them in another space, the […]
How Much Does a Wedding Photographer on Maui Typically Charge?

Weddings are moments of pure joy and celebration, and capturing these precious moments through photography is an essential part of the experience. Among the myriad […]
Say Goodbye to Leaks and Damage: The Ultimate Roof Restoration Solutions in Brisbane

With regards to the integrity of your home, not many things are basically as vital as a very much maintained roof. In Brisbane, where the […]
Exploring the Capabilities of AI-Assisted Document Composition

In this modern age, technology has changed many parts of our lives, including how we do things like write essays. The development of Artificial Intelligence […]
Your Access to 24/7 Emergency Repair Services

Emergency situations can happen anytime and to anyone, which means that they require immediate action and response. It is really unpredictable and needs the right […]
Essential Guitar Techniques for Aspiring Musicians

The guitar is a versatile and captivating instrument that has the power to move hearts and ignite musical passion. Aspiring musicians who wish to master […]
The Challenges To Surpass When Starting A New Business

Starting a new business is undeniably challenging. From creating and forming it, it is always a challenge to start it with dedication. If you look […]
How to Evaluate a New Business for Investment

A successful investment decision is built on a combination of quantitative analysis and qualitative assessment. No single factor can determine the viability of a new […]
Why Dental Marketing Needs to Embrace the Science of Colour Psychology

The Hidden Power of Colour in Healthcare Communications In an increasingly competitive healthcare landscape, dental practices are discovering that successful patient engagement extends far beyond […]
Cold Chain Management Supporting Freshness Across Time-Critical Product Deliveries

Proper handling keeps valuable materials in a stable condition from dispatch until arrival. Cold chain methods help maintain a suitable temperature through each stage without […]
Why Some Website Visitors Become Customers While Others Leave

Every website attracts a mix of visitors with different intentions. Some arrive ready to take action, while others are simply gathering information or comparing options. […]
How Circadian Rhythm Alignment Improves Your Dental Treatment Outcomes

Understanding the Connection Between Body Clocks and Oral Health When patients visit a dentist Port Macquarie or elsewhere, they typically focus on the treatment itself […]
Home Security Systems Helping Families Monitor Properties From Anywhere Conveniently Today

Keeping homes protected has become easier for busy households today. Parents working outside often want simple ways to check entrances, outdoor spaces, or parked vehicles […]
Sell Homes Quickly Without Repairs Through Direct Cash Offers Without Delays

Managing property concerns can feel stressful when urgent decisions arise and time feels limited. Many owners look for simple ways to move forward without spending […]
Advanced Lien Enforcement: How Strategic Litigation Maximizes Complex Payment Recoveries

Construction payment disputes often carry pressure across ongoing project timelines. Delays and refusals gradually create financial strain among involved parties. Professionals begin seeking structured legal […]
Quick Techniques for Collecting Favorite Social Media Video Clips

People often like saving memorable online moments for later viewing. A short clip can hold learning ideas, creative inspiration, or personal memories worth keeping. Many […]

